Soccer championship Euro 2016 - A weekend project, from July 2016
This is the data-preprocessing part of a blog post that has most of its visual content in a second part.
Part 1: preprocessing the data
I wrote this in July 2016, to make myself familiar with the R packages
ggplot2and other tidyverse packages. Exploratory Analysis of an Euro 2016 Betting Game. Predictions were made, just for fun (and a small amount of prize money), by a group of players (colleagues, their friends and family members) from my workplace in Germany.
Some definition of terms: In this context,
- Player means ‘Participant in the Betting Game’, not ‘Professional Soccer Player’ in one of the matches played during Euro 2016.
- Bet means ‘Score’ (in goals, e.g. 2:1): predicted result of a match at Euro 2016
- Prediction means ‘more or less educated guess’ made by some colleague of mine, or one of his/her friends, or family member. It does not mean ‘prediction’ in a machine-learning sense (e.g, as a result of fitting a model)
In 2016 I submitted the original version of this post to Rpubs.com, the default website to upload to from within the Rstudio IDE, but the Rpubs website has evolved to a dump of countless low-quality submissions of student homework, and I want my content at a central place. Also, the previous blog post was long and monolithic. Therefore, I’ve split it up and reposted it here.
This blogpost is just the boring but necessary preprocessing part. For the exploratory analysis, read part 2 of this post.
About the dataset
There were ~300 players predicting scores of the ~50 games during the Euro2016. This means there are 300 * 50 = 15000 predicions to analyze, but in fact there are only around 13000. This is because many players dropped out of the game, or lost interest during the Euro 2016, which lasted for 3 weeks. Nearly all players made full predctions for the group stage, but during the Knock-Out Stage of the Euro 2016, there were only brief periods of about 2 to 4 days, when players had to make their bets. Apparently, many people just missed their deadlines.
The rules of the betting game are too complicated to explain here. Probably the most important rule is that each successful prediction gets some reward points. Predicting the exact end result gets more points that getting just the tendency (win/draw/loss) right. All players had a set of 5 or so ‘Joker’ games available, which double the reward points earned. Players were free to assign this ‘doubling’ reward to any upcoming soccer game. Of course people used their favorite teams, and/or those games they were most certain about with respect to the end result.
Data preparation
The dataset of the player’s bets/predictions is not public, because there are full names of real people inside. Maybe I’ll show anonymized results of a small part of it at the end of this post. In 2016, I’ve used a little script to screen-scraped the data from the (internal) website, and then I copied it all together into a big csv-file.
Data analysis
Data preprocessing
R packages needed
library(lubridate)
library(dplyr)
library(tidyr) # separate
library(purrr) # functional programming
library(stringr)
library(readr)
library(ggplot2)
library(assertthat) # is.writeableRead in the data files
We need
- the final bets (13621 rows)
- true end results of the games played (51 matches)
- prize money winners (36 people)
datadir <- "data_private/gfzock"
see_if(is.readable(datadir))## [1] FALSE
## attr(,"msg")
## [1] "Path 'data_private/gfzock' does not exist"infile1 <- here::here(datadir, "EM2016_compiled_final.csv")
infile2 <- here::here(datadir, "real_games_scores_full.txt")
infile3 <- here::here(datadir, "gfzock_prize-money-winners.csv")
see_if(is.readable(infile1))## [1] TRUEeuro16games_final <- read_tsv(infile2, col_names = FALSE)
see_if(is.readable(infile2))## [1] TRUEeuro16bets_per_game1 <- readLines(infile1)
see_if(is.readable(infile3))## [1] TRUEplayers_winners <- read_csv(infile3) %>%
separate(col = Player,
into = c("player_last_name", "player_first_name"),
sep = ",",
remove = TRUE)For now, we will only be using character vector euro16bets_per_game1. The other two input files will be dealt with later.
The character vector euro16bets_per_game1 is 13627 elements long. Some complex preprocessing is necessary to convert it into two data frames:
- A data frame of games played
- A data frame of bets by player and game.
We make two passes over the character vector.
Read in games-data
First, detect section markers in euro16bets_per_game1. Lines starting with “#” mark a new section. Each section-marker line represents a new games, and contains few elements of game metadata. It looks like this
#;51;POR;FRA;2016-07-10 21:01:01
This means:
Game 51 was Portugal vs France, it happened on July 10, 2016.
euro16games_ind <- str_detect(pattern = "^#",string = euro16bets_per_game1)
#
euro16games <- tbl_df(data = euro16bets_per_game1[euro16games_ind]) %>%
separate(value, into = str_trim(c("mark", "game_nr",
"team_a","team_b","game_date")),
sep = ";") %>%
mutate(game_nr = as.integer(game_nr),
game_date = ymd_hms(game_date),
mark = NULL) %>%
mutate(stage = ifelse(game_nr > 36, "knockout", "group"))
glimpse(euro16games, width = 50)## Observations: 51
## Variables: 5
## $ game_nr <int> 51, 50, 49, 48, 47, 46, 45,...
## $ team_a <chr> "POR", "GER", "POR", "FRA",...
## $ team_b <chr> "FRA", "FRA", "WAL", "ISL",...
## $ game_date <dttm> 2016-07-10 21:01:01, 2016-...
## $ stage <chr> "knockout", "knockout", "kn...Find number of betting participants per game
# remove empty lines
euro16_empty <- str_detect(pattern = "^$", string = euro16bets_per_game1)
euro16bets_per_game2 <- euro16bets_per_game1[!euro16_empty]Find section-marker positions
section_marker_posns <- which(str_detect(pattern = "^#",
string = euro16bets_per_game2))
game_metadata <- euro16bets_per_game2[section_marker_posns]Find the number of bets per game:
numbets_last_section <- length(euro16bets_per_game2) - tail(section_marker_posns,1)
num_of_bets <- c(diff(section_marker_posns)-1, numbets_last_section)
# Convert num_of_bets to a named vector:
names(num_of_bets) <- game_metadataThe num_of_bets vector is sorted by date, in reverse order, youngest last. The last 3 elements are the first games played:
tail(num_of_bets,3)## #;3;WAL;SVK;2016-06-11 18:01:01 #;2;ALB;SUI;2016-06-11 15:01:01
## 274 279
## #;1;FRA;ROU;2016-06-10 21:13:10
## 280How many players participated over the course of the tournament?
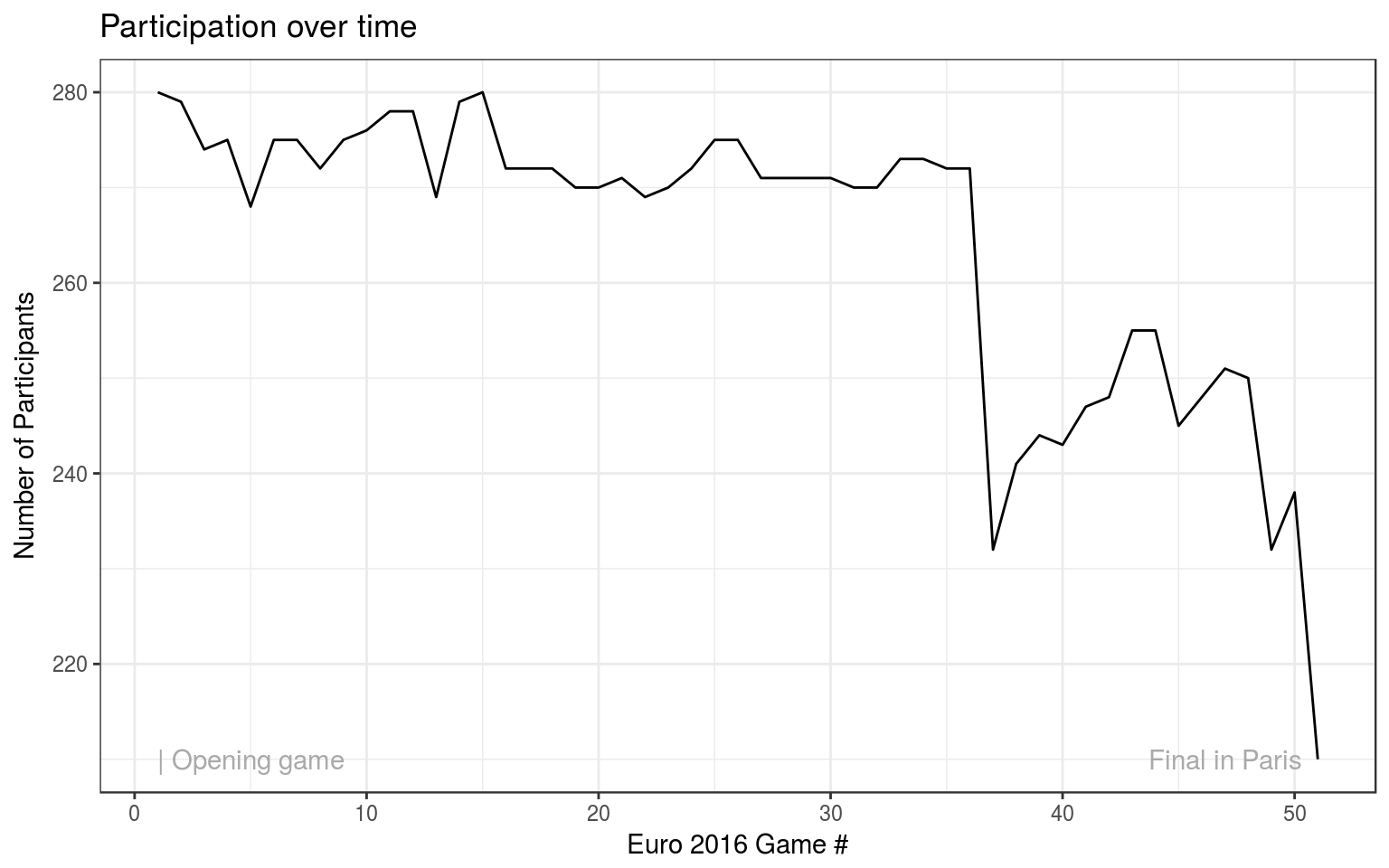
There was a bump in the transition from group stage to KO-stage, because many players missed to register their bets before the submission deadline.
Data frame 2: bets by game and player
Removing empty lines and marker lines from infile euro16bets_per_game1 (13627 lines) created euro16bets_per_game2, a vector of 13525 elements.
In a second pass over euro16bets_per_game2, split the vector into a list of vectors, then convert to data frame.
game <- map2(names(num_of_bets), num_of_bets+1, rep) %>%
unlist()
euro16bets_per_game <- cbind(euro16bets_per_game2, game)
euro16bets_per_game <- euro16bets_per_game %>%
as_data_frame() %>%
rename("betstr" = "euro16bets_per_game2") %>%
filter(str_detect(betstr, "#;") ==FALSE )Convert bets into data frame with meaningful column names
euro16bets_per_game <- euro16bets_per_game %>%
separate(game, sep=";", remove = TRUE, into = c("x", "game_nr", "y")) %>%
mutate(game_nr = as.integer(game_nr))
euro16bets_per_game <- euro16bets_per_game %>%
separate(betstr, sep=";",remove = TRUE,
into=c("player_last_name", "player_first_name",
"team_a_goals","team_b_goals",
"is_joker", "irrelev")) %>%
mutate_if(is.character, str_trim) %>%
mutate(team_a_goals = as.integer(team_a_goals),
team_b_goals = as.integer(team_b_goals),
tendency= ifelse(
team_a_goals == team_b_goals, "draw",
ifelse(
team_a_goals > team_b_goals, "team_a",
"team_b"))) %>%
select(-x, -y, -irrelev)
euro16bets_per_game$is_joker <- map_lgl(euro16bets_per_game$is_joker,
function(x) ifelse(x == "", FALSE, TRUE))The structure of the data frame now looks like this:
## Observations: 13,474
## Variables: 7
## $ player_last_name <chr> ...
## $ player_first_name <chr> ...
## $ team_a_goals <int> ...
## $ team_b_goals <int> ...
## $ is_joker <lgl> ...
## $ game_nr <int> ...
## $ tendency <chr> ...The column tendency indicates what the player predicted as a winner for that game. Values for tendency are team_a, team_b, draw, NA.
Extract Unique Players
players <- euro16bets_per_game %>%
select(player_last_name, player_first_name) %>%
mutate(player_last_name=str_trim(player_last_name), player_first_name=str_trim(player_first_name)) %>%
unique() %>%
arrange(player_last_name, player_first_name)There are 286 players.
Read in: list of players who won prize money
colnames(players_winners) <- players_winners %>%
colnames() %>%
make.names() %>%
tolower()
players_winners <- players_winners %>%
mutate(player_first_name = str_trim(player_first_name),
player_last_name = str_trim(player_last_name)) %>%
rename( "fraction_pct" = "portion....", "amount_euro"="prize..euro.")There are 36 players who got prize money.
Join them with players table:
(We made sure by data cleanup that all winning entries can be mapped to the players table.)
players_winners$is_winner <- TRUE
players <- players %>%
left_join(players_winners,
by = c( "player_last_name", "player_first_name")) %>%
mutate(is_winner=! is.na(is_winner)) - Create joint table of players and their bets
games_players <- euro16bets_per_game %>%
inner_join(euro16games, by=c("game_nr"))- Read in final games scores from
infile3, as they were played.
# add full names of countries, e.g. POR -> Portugal
names(euro16games_final) <- c("team_a_long", "team_b_long", "result")
euro16games_final <- euro16games_final %>%
separate(col = result, sep = ":",
into = c("team_a_goals", "team_b_goals")) %>%
mutate(team_a_goals= as.numeric(team_a_goals),
team_b_goals= as.numeric(team_b_goals)) %>%
mutate(team_a_name = toupper(str_sub(team_a_long, 1,3)),
team_b_name = toupper(str_sub( team_b_long, 1,3))) %>%
select(team_a_long, team_a_name, team_a_goals,
team_b_goals, team_b_name, team_b_long)
# add draws
euro16games_final <- euro16games_final %>%
mutate(is_draw = ifelse(team_a_goals == team_b_goals,
TRUE, FALSE))
glimpse(euro16games_final, width=30)## Observations: 51
## Variables: 7
## $ team_a_long <chr> "Por...
## $ team_a_name <chr> "POR...
## $ team_a_goals <dbl> 1, 0...
## $ team_b_goals <dbl> 0, 2...
## $ team_b_name <chr> "FRA...
## $ team_b_long <chr> "Fra...
## $ is_draw <lgl> FALS...good.tmp <- unique(c(euro16games$team_a, euro16games$team_b))
updthis.tmp <- unique(c(euro16games_final$team_a_name, euro16games_final$team_b_name))
(updthis <- setdiff(updthis.tmp, good.tmp))## [1] "SWI" "ICE" "NOR" "SLO" "ROM" "SPA" "AUS" "IRE"(good <- setdiff(good.tmp, updthis.tmp))## [1] "SUI" "ISL" "NIR" "SVK" "ROU" "ESP" "AUT" "IRL"update_euro16games_final <- function(x,y){
euro16games_final[euro16games_final$team_a_name == x, "team_a_name"] <<- y
euro16games_final[euro16games_final$team_b_name == x, "team_b_name"] <<- y
}
# update in-place
walk2(updthis, good, update_euro16games_final)
# add game_nr and date
euro16games_final <- euro16games_final %>%
inner_join(euro16games, by=c("team_a_name"="team_a", "team_b_name"="team_b")) %>%
arrange(desc(game_nr))
# add tendency
euro16games_final <- euro16games_final %>%
mutate(tendency= ifelse(team_a_goals == team_b_goals, "draw", ifelse(team_a_goals > team_b_goals, "team_a", "team_b")))
num_draws <- euro16games_final %>%
filter(is_draw == TRUE) %>%
count() %>%
as.integer()
glimpse(euro16games_final, width = 50)## Observations: 51
## Variables: 11
## $ team_a_long <chr> "Portugal", "Germany", "...
## $ team_a_name <chr> "POR", "GER", "POR", "FR...
## $ team_a_goals <dbl> 1, 0, 2, 5, 2, 3, 1, 1, ...
## $ team_b_goals <dbl> 0, 2, 0, 2, 1, 1, 2, 2, ...
## $ team_b_name <chr> "FRA", "FRA", "WAL", "IS...
## $ team_b_long <chr> "France", "France", "Wal...
## $ is_draw <lgl> FALSE, FALSE, FALSE, FAL...
## $ game_nr <int> 51, 50, 49, 48, 47, 46, ...
## $ game_date <dttm> 2016-07-10 21:01:01, 20...
## $ stage <chr> "knockout", "knockout", ...
## $ tendency <chr> "team_a", "team_b", "tea...- Save results to .RData file, which will be used in part2:
see_if(is.writeable(datadir))
outfile <- here::here(datadir, "gfzock_euro2016_preprocessed.RData")
see_if(is.writeable(outfile))
save.image(file=outfile) End of preprocessing
- Continue reading in a second blog post, part2.